Adding little touches of AI to your projects
🇫🇷 Bonjour
TL;DR: I used Mistral with its OCR and structured output functionality to pre-populate a form on my SAAS.
I just implemented a feature that leverages Mistral to automate a form on my SAAS iSignif. And I promise you, it’s not just a chatbot or an MCP server.
Have you heard of the MCP protocol, which allows you to connect your service to a Language Model (LLM)? I guess so, and to be honest, I spent a lot of time trying to implement it for my SAAS iSignif.
Then I came across this video: “Don’t just set up a chatbot: build AI that works before you ask” (Youtube). So I asked myself if the user really wanted to talk to a chatbot instead of using an interface they were familiar with. And it’s clear that new AI tools can offer so much more than a simple chatbot.
My product
I created iSignif.fr a few years ago to automate the process of serving documents between lawyers and bailiffs. The process is as follows:
- A lawyer files a document. It’s actually a PDF document that a bailiff must deliver by hand to one or more recipients.
- iSignif selects a bailiff based on the postal code where the document is to be served.
- The bailiff is contacted and they handle the request.
The first step is manual: the lawyer must fill out a form, specify the recipients, and upload their files. This is the laborious part where the user must copy the information from their letter and enter the information on the iSignif form. Some users do this several times a day, and a document can include more than a dozen recipients…
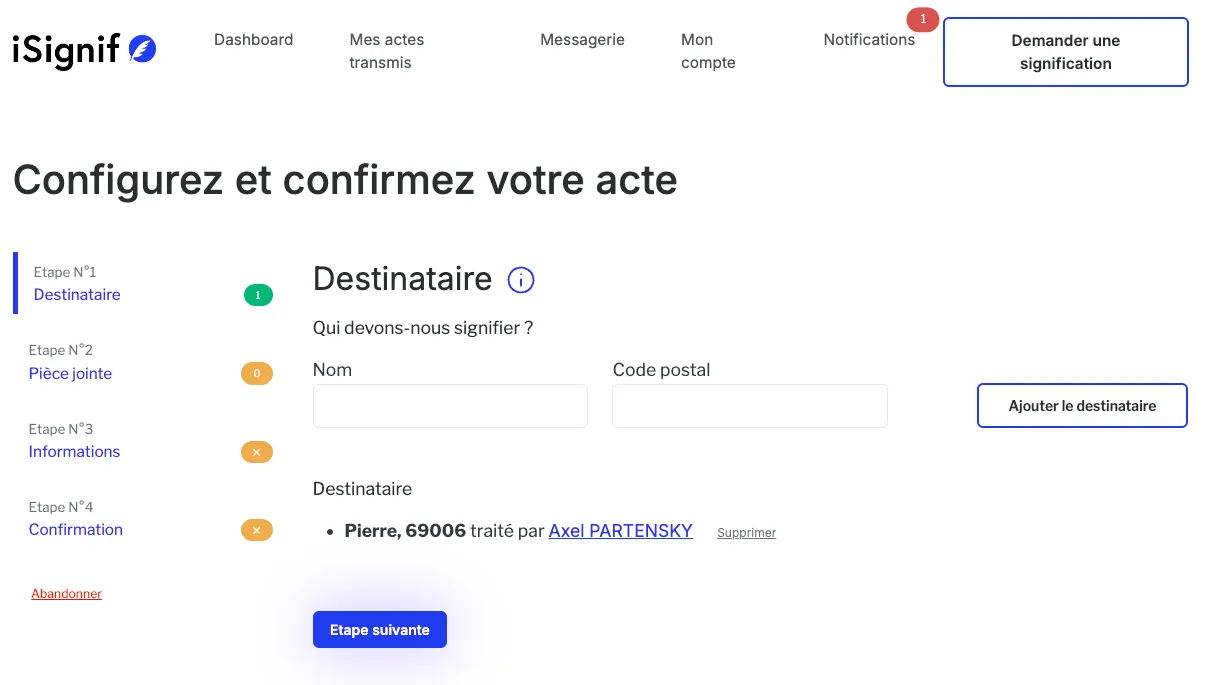
Perhaps you see where I’m going with this, but LLM tools can do this job perfectly well for the user. So my idea was to implement a feature that would simply pre-populate the form from the PDF.
In technical terms, this would involve:
- Extracting the content of the user’s document. I’m going to use an Optical Character Recognition (OCR) API to convert the document to text.
- Send the document content to an LLM to retrieve the information in a given format.
- Create the requested database resources.
Proof of concept
I immediately thought of Mistral, a French/European leader in artificial intelligence and language models (LLM). I chose them because:
– It’s a French company, which reassures users about the processing of their data. – It has a JavaScript library that allows you to do everything. – The prices are very affordable.
Before getting into anything complicated, I thought I’d start by setting up a simple script that would take a file and make API calls to isignif.fr/api/v1.
Okay, I’ll initialize a Node.js project to try this out:
mkdir /tmp/isignif-pdf
cd /tmp/isignif-pdf
npm init -yExtracting information from a document has a name: Optical Character Recognition (OCR). This is the action of recognizing characters in a document, or extracting the encoded text and returning the formatted content.
Mistral allows you to do this. Let’s give it a quick test:
npm install @mistralai/mistralai
npm install --save-dev @types/node// main.mjs
import { Mistral } from "@mistralai/mistralai";
import { openAsBlob } from "node:fs";
import process from "node:process";
// initialize Mistral
const apiKey = process.env.MISTRAL_API_KEY;
if (!apiKey) throw new Error("Missing OpenAI API key");
const mistral = new Mistral({ apiKey });
// open PDF
const blob = await openAsBlob("./sample.pdf");
// upload file to Mistral for OCR and get the URL of the resource
const fileRes = await mistral.files.upload({
file: blob,
purpose: "ocr",
});
const fileUrl = await mistral.files.getSignedUrl({ fileId: fileRes.id });
// process the OCR and get the result
const ocrRes = await mistral.ocr.process({
model: "mistral-ocr-latest",
document: {
documentUrl: fileUrl.url,
type: "document_url",
},
});
console.log(ocrRes.pages);This returns a table of pages with the PDF content in Markdown format!
[
{
"index": 0,
"markdown": "# COUR D'APPEL DE DIJON \nLe greffier de la cour d'appel vous avise de la déclaration d'appel dans l'affaire mentionnée ci-dessus dont l'objet est :\n...",
"images": [],
"dimensions": { "dpi": 200, "height": 2339, "width": 1654 }
}
]Now that we have the document content, we need to ask the LLM to extract the information in JSON schema, containing the data we’re interested in. In jargon, this is called a Structured Output.
The key step is to define what we want to obtain using a JSON schema. To declare the JSON schema more elegantly, it’s recommended to use the Zod library.
npm i zodWe’ll declare a ResponseFormat object that contains our format.
// main.mjs
import { z } from "zod";
// ... code before
const ResponseFormat = z.object({
meanings: z.array(
z
.object({
zipCode: z
.string()
.describe("the postal code of the service (often 5 digits)"),
name: z
.string()
.describe(
"the name of the service, which allows the user to easily find it. This is often the location that tells the bailiff where to serve the document (example: 'Carrefour Meyzieu')",
),
})
.describe("The service to be served"),
),
actType: z.string(),
reference: z
.string()
.optional()
.describe(
"A reference noted on the document to identify the request and make it easy to find",
),
});The important part is to properly specify the .describe() statements. This is what will allow the LLM to understand our schema.
Now, we can use the mistral.chat.parse method to extract the information and transform it into a ResponseFormat. Here again, let’s try to create a conversation that allows the LLM to have as much context as possible. We create two messages:
"system", which will influence the behavior of our LLM"user", which will formalize the request in text form and will then contain the contents of the file
// main.mjs
// ... code before
const ocrFileContent = ocrRes.pages.map((p) => p.markdown).join("\n---\n");
const res = await mistral.chat.parse({
model: "ministral-3b-latest",
messages: [
{
role: "system",
content: `You manage a platform called iSignif. We simplify the process of serving documents between lawyers and bailiffs. The principle is that:
1. a service is a request to a bailiff to serve a letter to a recipient. A service only requires a postal code so that iSIgnif can find a competent bailiff in the department.
2. a document groups several service requests under the same document type.
For example, the user will request that their document "Court Summons" be served in Lyon (69), Marseille (13), and Toulouse (31). Three different bailiffs will be contacted. When the three bailiffs have delivered the summons to their recipient, the document will be marked as complete..`,
},
{
role: "user",
content: `Hello, I would like to create a document on iSignif. Here is the content of my document, which contains the information for my document and the notifications (there can only be one). Can you extract the information so I can create the document myself? \n\n\n${ocrFileContent}`,
},
],
responseFormat: ResponseFormat,
});
const data = ResponseFormat.parse(res.choices?.at(0)?.message?.parsed);
console.log(data);{
"significations": [
{ "zipCode": "21000", "name": "Dijon" },
{ "zipCode": "21700", "name": "Nuits-Saint-Georges" },
{ "zipCode": "75009", "name": "Paris" }
],
"actType": "Assignation en justice",
"reference": "25/00258"
}Oh my! I should point out that I don’t have much experience in prompt engineering, but the result is very satisfying.
Now that we have the data, we just need to run the actions on the iSignif API. I won’t go into detail about this part here, as it’s irrelevant to the topic of this article, but you can view the code in the project repository.
Setting up an HTTP API
Everything is working correctly, the Proof of Concept is promising, all that’s left is to implement it on my project in… Ruby on Rails!
OK, I’ve just completed my POC in Node.js. Mistral doesn’t offer an SDK for Ruby, and I don’t want to complicate things.
In my opinion, it’s entirely possible to mix technologies using small microservices. In some cases, this can complicate the infrastructure, but I feel like it’s a pretty good fit here.
I was thinking of setting up a route on my API that takes as parameters:
file, the file of theiSignifApiUrl, the URL of the API to calliSignifToken, the JWT token used to authenticate with iSignif
So I refactored my POC to have a more generic method
// ocr.ts
// ...
export function useIsignifOCR(
mistral: Mistral,
isignifBaseUrl: string,
token = "",
) {
const isignifApi = new IsignifApi({
/*...*/
});
const ResponseFormat = z.object({
/*...*/
});
async function computeFile(file: File) {
// ...
return { ...data, url: `${isignifHost}/acts/${act.id}` };
}
return { computeFile };
}I told myself that I would set up a small server with Hono.
import { serve } from "@hono/node-server";
import { zValidator } from "@hono/zod-validator";
import { Mistral } from "@mistralai/mistralai";
import { Hono } from "hono";
import { z } from "zod";
import { useIsignifOCR } from "./ocr.ts";
// setup Mistral
const apiKey = process.env.MISTRAL_API_KEY;
if (!apiKey) throw new Error("Missing OpenAI API key");
const mistral = new Mistral({ apiKey });
const app = new Hono();
app.post(
"/guess-pdf",
zValidator(
"form",
z.object({
file: z
.instanceof(File)
.refine((file) => file.type === "application/pdf", {
message: "File must be a PDF",
}),
iSignifToken: z.string(),
iSignifApiUrl: z.string().default("http://isignif.fr/api/v1"),
}),
),
async (c) => {
const { file, iSignifApiUrl, iSignifToken } = c.req.valid("form");
const { computeFile } = useIsignifOCR(mistral, iSignifApiUrl, iSignifToken);
const res = await computeFile(file);
return c.redirect(res.url);
},
);
serve({ fetch: app.fetch, port: 4000 }, (info) => {
console.log(`Server is running on http://localhost:${info.port}`);
});The principle is very basic, but more importantly, it can be connected to a simple HTML form. The c.redirect() method will redirect the user to the action URL once it has been created.
<form
method="POST"
action="http://localhost:4000/guess-pdf"
enctype="multipart/form-data"
>
<input type="file" name="file" accept="application/pdf" required />
<input type="hidden" name="iSignifToken" value="xxxx" />
<input
type="hidden"
name="iSignifApiUrl"
value="https://localhost:3000/api/v1"
/>
<input type="submit" />
</form>…and here is the result in production!
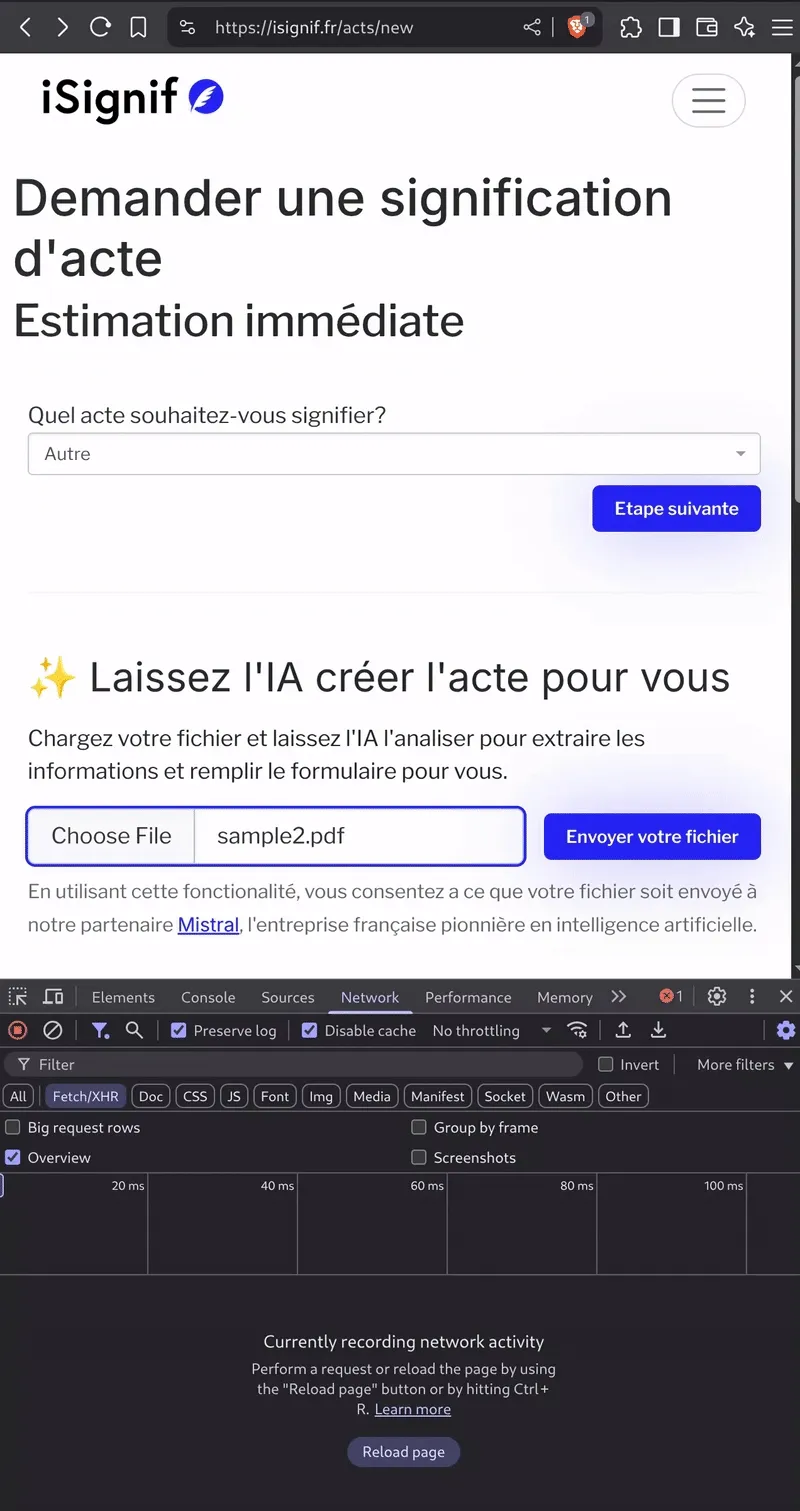
Conclusion
In my opinion, AI shouldn’t completely replace the way we interact with a service, but rather facilitate it. This example demonstrates this very well: AI doesn’t replace the form; it helps the user fill it out.
This also allows me to continue offering the old experience to the user, and therefore give them a choice. This is very important in cases where the user doesn’t want to use this feature.
I’m very happy with the result and I plan to take it even further.
If you’re curious, you can take a look at the project: https://github.com/isignif/pdf-ai.
See other related posts
This tutorial show you how to setup dependency injection with TypeORM and Inversify libraries